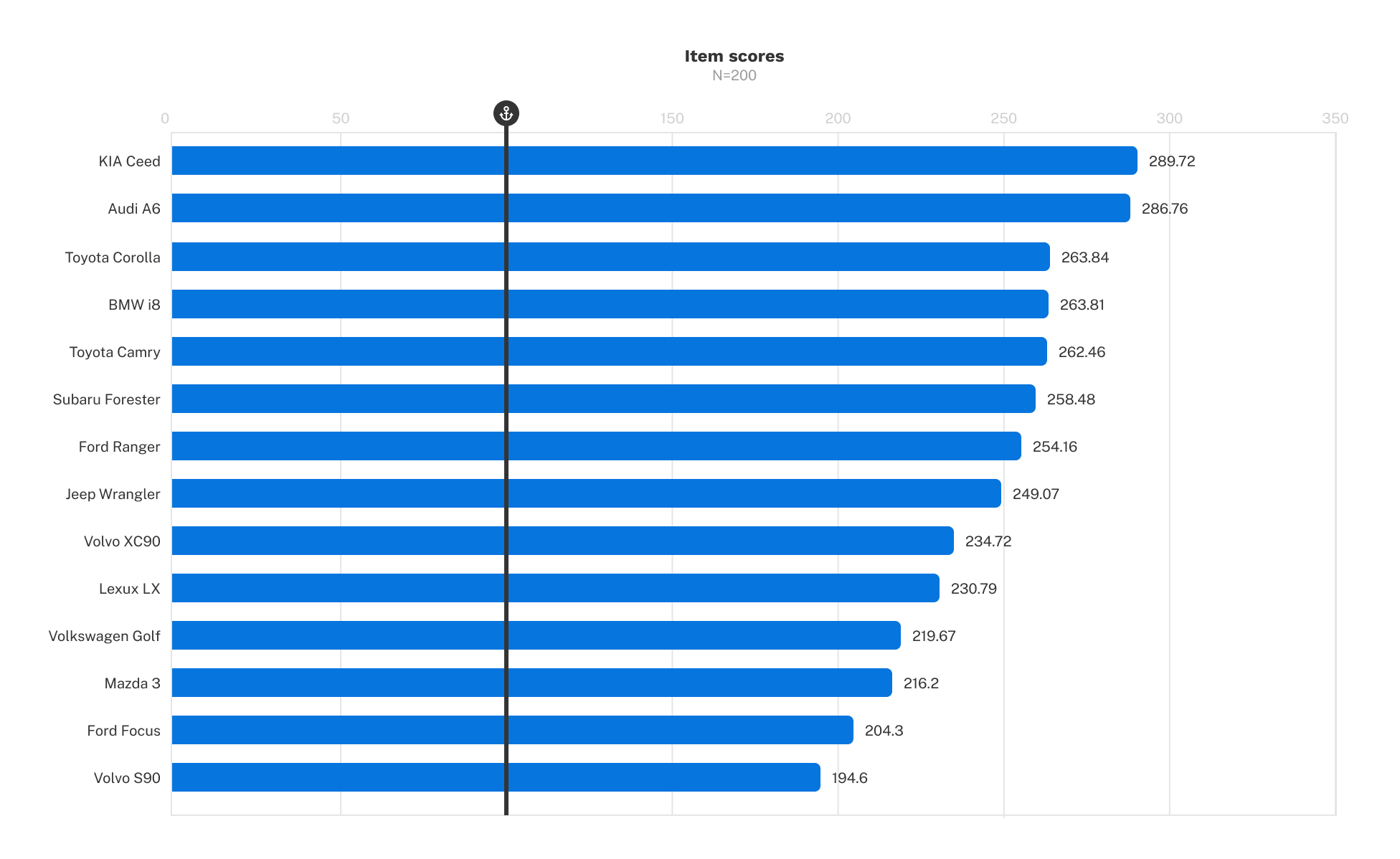
Individual scores can be downloaded in two formats: raw and rescaled.
Both include a MaxDiff_Fit (RLH) column. This fit statistic, based on root likelihood, indicates how well a respondent's estimated utility scores predict their actual choices. RLH is the geometric mean of the probabilities of choice produced by the utility scores of what the respondent selected.
A Model fit relative quality column categorizes each respondent as Good, Moderate, or Poor, provided each item was shown at least twice. This rating accounts for task difficulty — predicting one answer from two options is easier than from five. Thresholds are determined by simulating random respondents across various MaxDiff exercise sizes and identifying cutoffs that maximize detection of random responding while minimizing false positives.
When relevant items MaxDiff is used, a Missing items export as blank fields setting appears before download. When off (default), imputed utility scores for missing items are included. When on, blanks replace imputed values for items not shown to a respondent.