Introduction
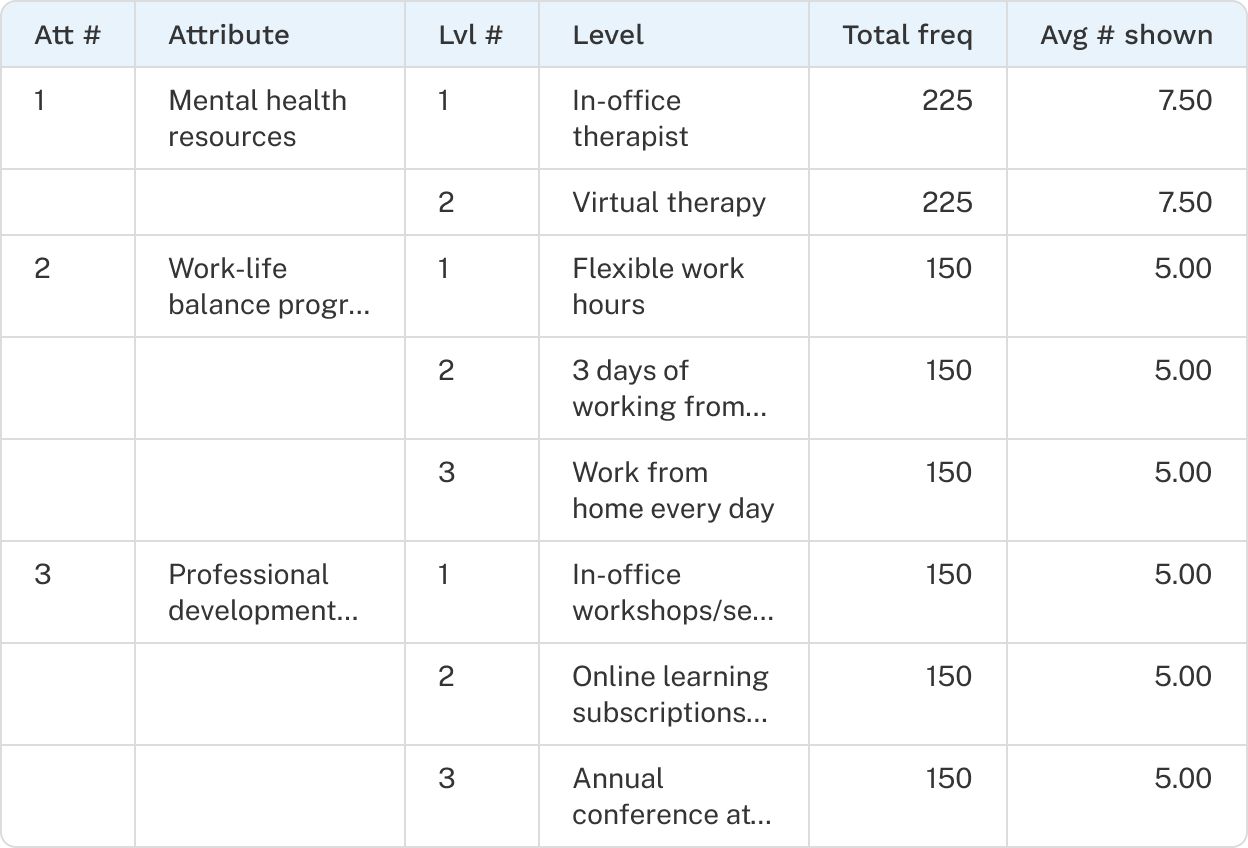
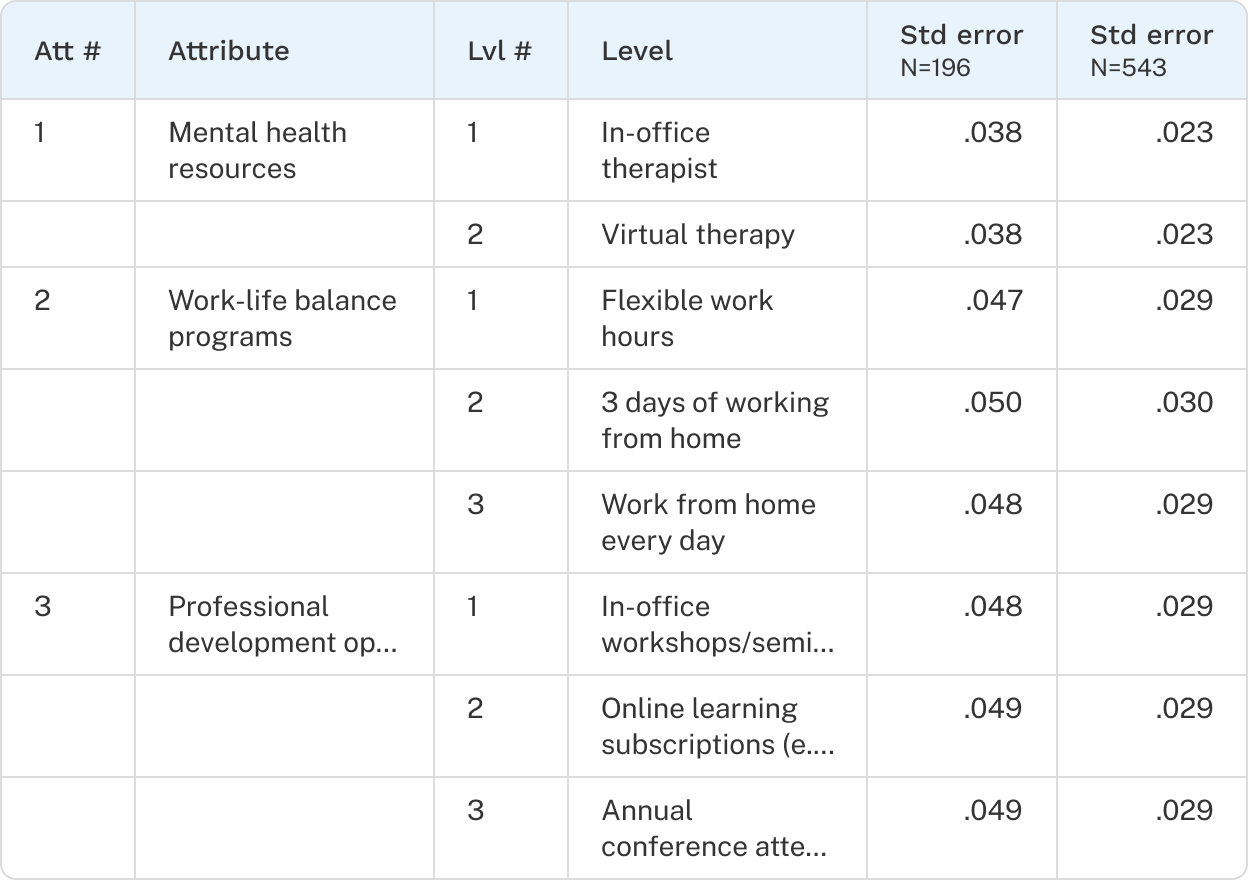
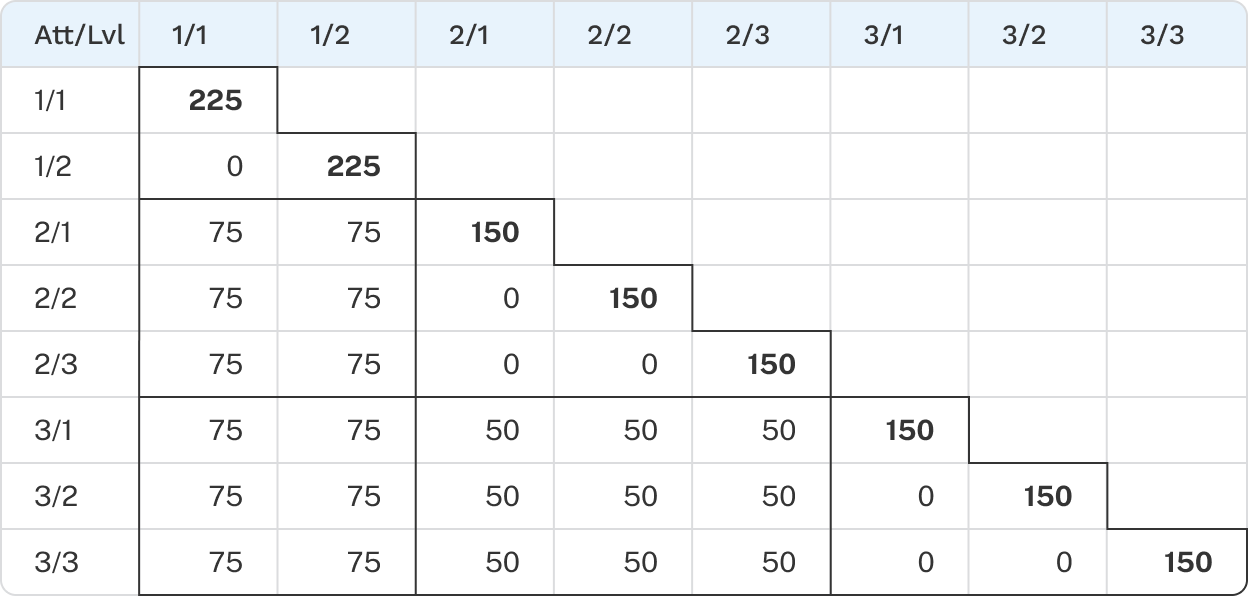
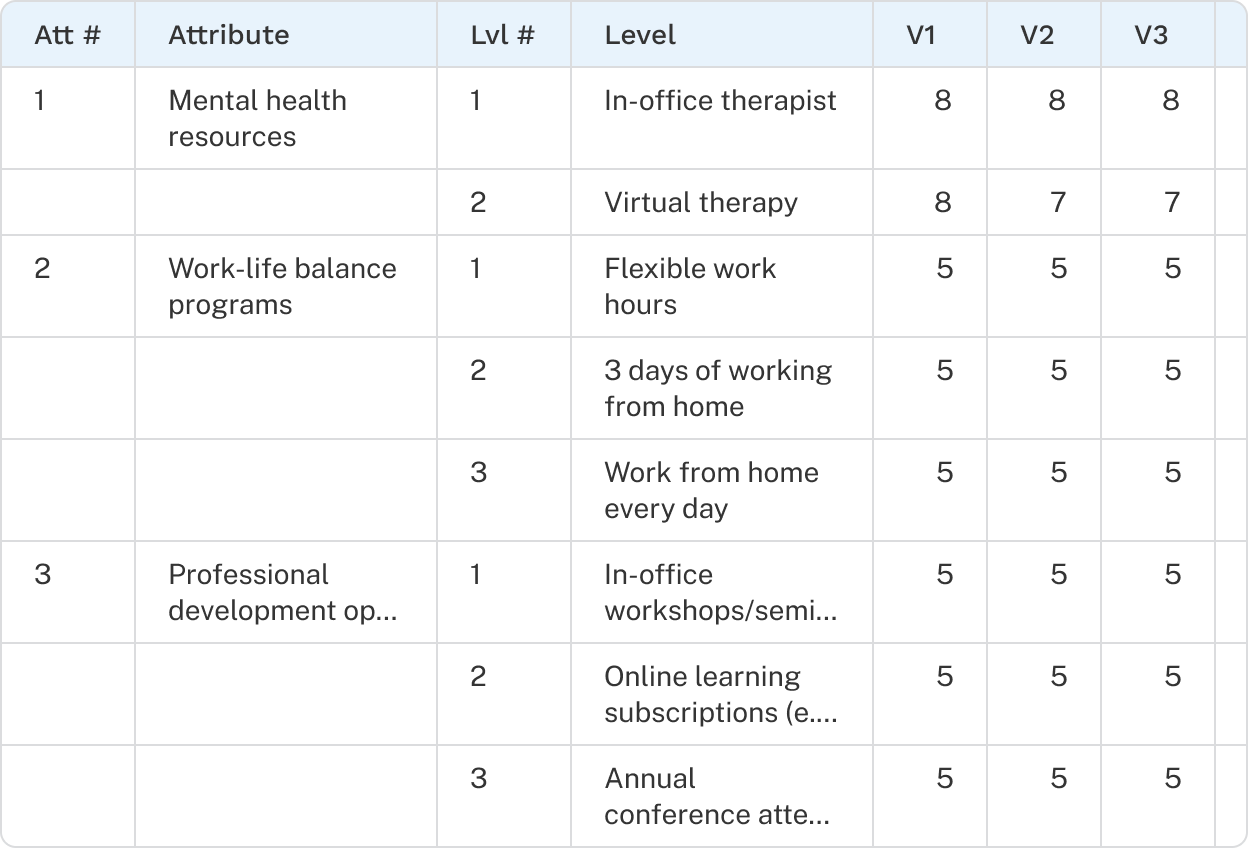
A design is the combination of tasks and concepts that respondents see in a CBC exercise. To reduce order bias and improve utility estimation, Discover generates multiple versions of a design so respondents receive different sets of questions. For example, a 30-version design produces 30 unique sets of tasks assigned to respondents in rotation. Some respondents may see the same version, but strong balance is maintained both within and across versions.
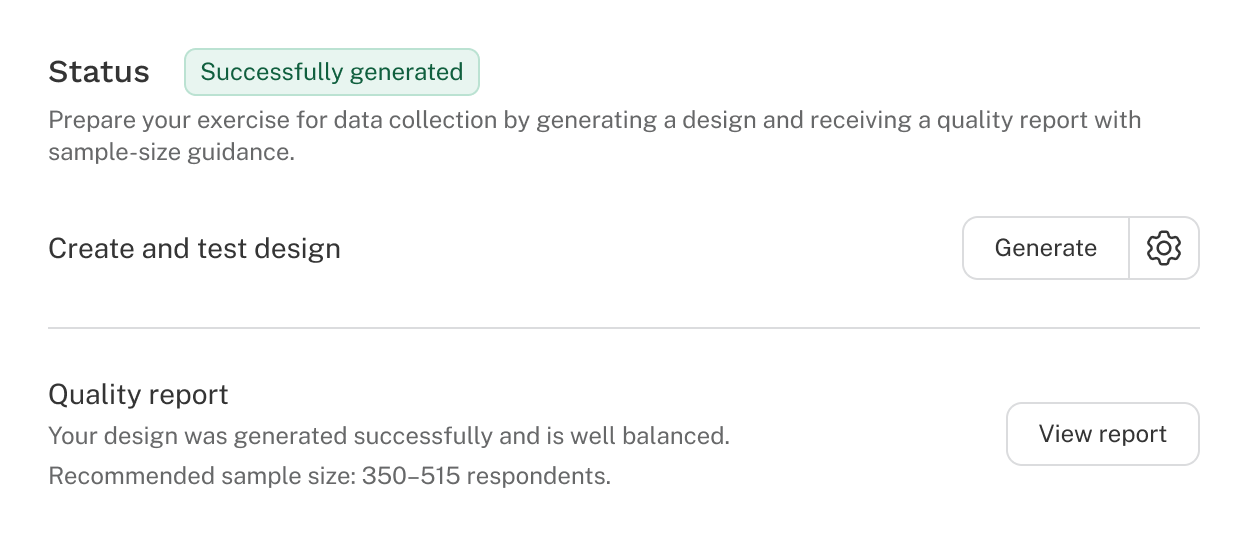
A valid design is required before you can publish your survey. You can view and generate the design from the Design tab of each CBC exercise.
Design statuses
- Successfully generated: The design is ready for data collection.
- Warning: The design is usable but may result in poor utility estimation. Notes are included with suggestions for improvement.
- Unusable: The design cannot produce reliable utilities. Address the listed issues and regenerate.
- Failed: The design could not be generated, typically due to too many prohibitions. Try generating again — if it continues to fail, contact support.
- Out of date: The design no longer matches the current exercise settings. Regenerate to reflect the latest changes.